Reachability Analysis: SCA "Killer Feature"?
Background
This is a post about a new technology that I believe has the potential to drastically change the way in which organizations choose automated tools for discovering and managing vulnerabilities in web application source code.
Maven’s Server-side Revolution
 In July of 2004, Maven v1.0 was released to the general public by Jason van Zyl - a project that was funded by and would eventually become part of the Apache Software Foundation’s suite of open source software products.
In July of 2004, Maven v1.0 was released to the general public by Jason van Zyl - a project that was funded by and would eventually become part of the Apache Software Foundation’s suite of open source software products.
Initially, Maven was used primarily as a Java build automation tool. Maven assisted developers in automating away critical steps in the software development lifecycle. Common steps that could be automated via Maven and a simple XML configuration file included:
- Test Runners (e.g. unit or integration tests)
- Compiling Java code to JVM bytecode
- Packaging Java Applications
- Deploying Java Applications to Remote Servers
Eventually, the scope of Apache’s Maven product expanded to include a new but very important killer feature. Before discussing this killer feature, let’s take a look at Wikipedia’s definition of a killer feature.
According to Wikipedia, a killer feature is a feature that is so fundamentally groundbreaking and important that a user will switch from a similar competitor product for the sole purpose of obtaining said new feature. It could be said that a killer feature revolutionizes the way in which users make use of a product such that the value proposition of other features pale in comparison.
Maven’s killer feature was third-party package management. Despite not being the first package manager supporting third-party code: Maven utilized a simple XML configuration structure, attached itself to one of the most popular back-end languages and launched a developer-driven marketing campaign backed with slick IDE integrations and a popular command-line interface.
Before long million’s of lines of open-source software was available at a developers fingertips and added little-to-no difficulty at the build step.
The difficult parts of including another developer’s code in your Java application where abstracted away so a developer could focus on building application logic rather than fumbling around with manual build processes.
With this new feature came a paradigm shift, resulting in server-side applications being comprised of first-party code from known authors, and third-party code from unknown authors. Software development become more collaborative overnight.
NPM’s Client-side Revolution
 Later in 2010, Isaac Z. Schlueter would launch NPM - a package manager for JavaScript-based applications.
Later in 2010, Isaac Z. Schlueter would launch NPM - a package manager for JavaScript-based applications.
With JavaScript being the only programming language supported by web browsers, NPM would allow client-side applications to consume open-source software across the web in a similar fashion to that of previous server-side package managers like Maven (NPM was also inspired by PHP’s “PEAR” and Perl’s “CPAN”).
NPM also made popular design choices by switching to JSON configuration files, a “safe serialization” format which is more appropriate for handling untrusted data than XML. It also offered more flexibility than XML which resulted in developers building on top of the package manager in a multitude of creative ways.
NPM could also be used as a tool in developing server-side applications, thanks to the rapid adoption of NodeJS. This meant a full-stack web application could be developed easily in-part with open-source software from developers across the web.
Third Party Code & Security Concerns

According to a study funded by Synopsys in 2020, nintey-nine percent (99%) of commercial code bases now include open source software.
The same study suggests an average of 445 open-source “components” exist in every commercial code-base - double the number reported in a 2018 study by the same authors.
The trend is clear, today’s web applications and the web applications of the future will be built fully or in part on open-source software.
This means that code from third party developers is more and more intermingled with first party code. This is a massive security risk.
- Third party developers may be malicious, and introduce vulnerable code into their package prior to it being integrated with your software.
- Third party developers may abandon a package, causing it to become outdated - and as a result vulnerable.
- Third party developers may sell or transfer ownership of an open-source package to a new owner with questionable integrity.
- Third party developers may also hold code to different standards than first-party code. This could result in vulnerabilities and bugs “accidentally” being introduced in your application.
Software Composition Analysis (SCA) vendors (e.g. Sonatype, Snyk, Semgrep) have been capitalizing on these issues for many years now.
Software Composition Analysis (SCA)
SCA tools analyze the digital “supply-chain” that feeds your first party software.
Typically these tools make use of open-source vulnerability databases like mitre.org (funded by DHS & CISA) in order to spot vulnerable software in your package manager and alert you that said package is not “safe for use”.
These SCA tools typically provide vulnerability severity scores (often CVSS) alongside a description of the vulnerability found, in order to convince you (the developer) to remove or upgrade your package/dependency.
What SCA tools do not tell you, is if your first-party code-base is actually capable of being exploited via the vulnerability found in your supply chain.
In other words, it’s possible that your expensive (often $100,000+ / year) SCA tooling is presenting you with very little signal in the midst of a lot of noise.
Signal vs Noise
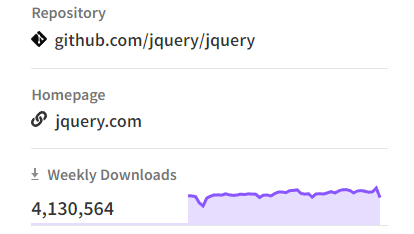
Despite falling in popularity in recent years, JQuery is still one of the most popular JavaScript libraries. On average, it recieves about 4,000,000 downloads each week via NPM.
The entire developer-facing public API of JQuery can be found at api.jquery.com. With a quick snippet of JavaScript, we can calculate how many public functions the JQuery API includes:
let n = 0
document.querySelectorAll(".entry-title").forEach(() => {
n += 1;
});
console.log(n) // returns 318 as of 11/28/2022
As of the time of writing this (11/28/2022) the JQuery public API had 318 functions.
In version 3.4 of JQuery (circa 2020) - two of JQuerie’s public API functions where found to be subject to cross-site-scripting (XSS) attacks. The vulnerable functions where $(selector).html() and $(selector).append().
This vulnerability was noted first on Github and later on various CVE databases. It typically scored between a medium and high severity finding, meaning that it would need to be remediated rapidly.
Shortly afterwards SCA tools began notifying million’s of website owners that JQuery had to be updated to 3.5.1 or greater, else the application JQuery ran inside of would be “compromised”.
Despite JQuery having 318 public functions, and only two of those functions being vulnerable - almost all SCA owners where notified that they had software compromised. If all functions in JQuery where used in an evenly distributed fashion, that would mean that despite only 1/159 applications making use of JQuery being affected by this vulnerability - 159/159 applications where notified by SCA.
That means that SCA tools likely had a false-positive rate of 99.3% in regards to this vulnerability. That is a lot of noise!
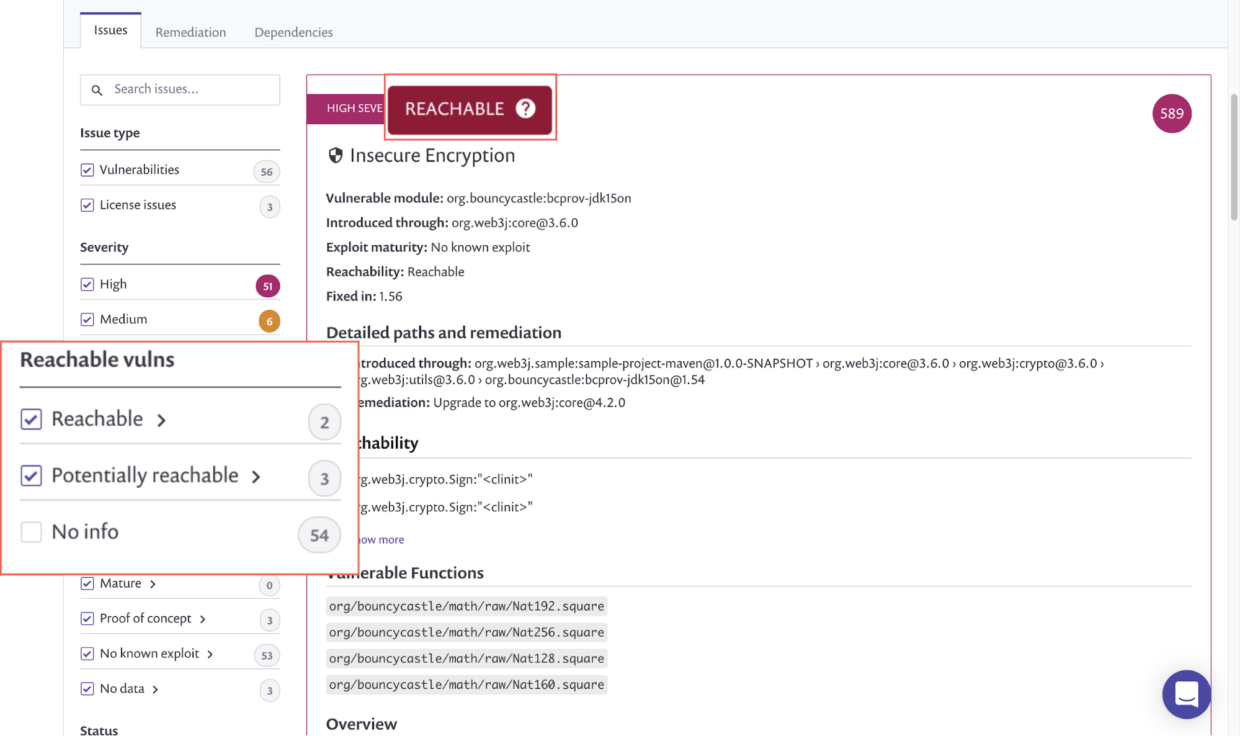
Reachability Analysis
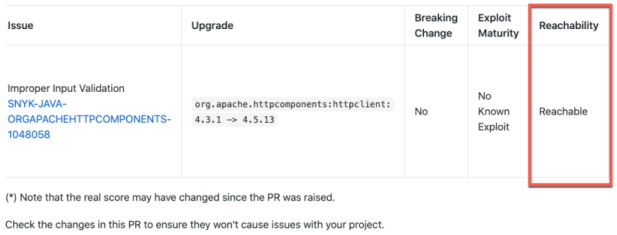
It’s 2022 and SCA tools are slowly but surely becoming more advanced. Semgrep and Snyk are now offering beta versions of a new feature called reachability.
According to a blog post by Snyk reachability is a combination of SCA and static analysis working in tandem.
First, SCA tooling detects third-party vulnerabilities the same way it always has.
Next, instead of throwing your organization into an emergency state whenever a high-severity vulnerability is found, static analysis code is run to detect if you are making use of said vulnerable function. Ideally this static analysis code would also do a check against the third-party library’s own code to ensure there are no internal calls to the vulnerable function as well.
The outcome of this process is that in a fully functioning SCA with near-perfect reachability, your organization should only be alerted if you are actually making use of vulnerable code - not simple incorporating a library with un-used vulnerable code.
This new technology is in it’s earliest phases, and often being sold as a “up-and-coming feature” - but as codebases continue to integrate more and more with third-party code I anticipate that in the next ten years this will become a killer feature for SCA.
Eventually it will be common knowledge that vulnerabilities exist everywhere on the web, and are abundant across open source software. Instead of wasting valuable developer time host-swapping libraries on a daily basis, smart reachability analysis will allow corporations to gain insight into ways in which their code is actually vulnerable and de-prioritize dead end work involving vulnerabilities that don’t affect your company’s software.
To conclude - my prediction is that in 10 years time (2033) SCA tools that don’t incorporate reachability analysis will be on their way out of the market and into the history books.